

Στο προηγούμενο εξάμηνο στα πλαίσια του μαθήματος “Μηχανική Μάθηση” το οποίο διδαχθήκαμε στο πρόγραμμα μεταπτυχιακών σπουδών Ευφυείς Τεχνολογίες Διαδικτύου εκπονήσαμε μία εργασία εξαμήνου η οποία ήταν σε μορφή διαγωνισμού στο Kaggle .
Αντικείμενο της εργασίας ήταν η επεξεργασία ακτινογραφιών και η διάγνωση τους σε τρεις κλάσσεις :
1) Χωρίς Ασθένεια
2) Βακτηριακή Πνευμονία
3) Ιογενής Πνευμονία
Η μηχανική μάθηση μπορεί να βοηθήσει δραστικά στην σωστή αναγνώριση της πνευμονίας και να βοηθήσει τους γιατρούς στην εξαγωγή χρήσιμων συμπερασμάτων.
Παρόλο που στο διαγωνισμό η ομάδα μας τα πήγε πολύ καλά τερματίζοντας δεύτερη δεν θα συμπεριλάβω το μοντέλο που αναπτύξαμε καθώς ο διαγωνισμός αυτός είναι ενεργός για το τρέχον εξάμηνο επομένως θα ήταν αδικία για όποιον έβρισκε το λινκ.
Στο παρακάτω σύντομο tutorial θα παρουσιάσω πώς μπορούμε να αναπτύξουμε ένα image classification μοντέλο το οποίο να διαβάζει μία ακτινογραφία την ταξινομεί σε μία από τις τρεις διαθέσιμες κατηγορίες: Πνευμονία , Ιική Πνευμονία , Υγιής .
Πριν ξεκινήσουμε όμως θα ήθελα να αναφέρω ορισμένους χρήσιμους ορισμούς των νευρωνικών δικτύων προκειμένου να καταλαβαίνουμε τι κάνουμε :
Χρήσιμοι ορισμοί :
1.InputLayer: Επίπεδο Εισόδου του νευρωνικού δικτύου
– Διαστάσεις του όγκου εισόδου (tensor shape)
2.Convolution2D: Επίπεδο Συνέλιξης
– Μορφολογία της εισόδου
– Αριθμός των φίλτρων συνέλιξης
– Διαστάσεις των φίλτρων συνέλιξης
– Συνάρτηση ενεργοποίησης
3.MaxPooing2D: Επίπεδο Υποδειγματοληψίας
– Διαστάσεις πλαισίου
– Βήμα μετατόπισης
4.ZeroPadding2D: Προσθέτει πλαίσιο με μηδενικά στον όγκο εισόδου
– Διαστάσεις του πλαισίου
5.Activation: Επίπεδο ενεργοποίησης. Εφαρμόζει συνάρτηση ενεργοποίησης στον
όγκο εξόδου του προηγούμενου επιπέδου
6.Dropout: Επίπεδο πρόληψης υπέρ-προσαρμογής
7.Dense: Πλήρες συνδεδεμένο επίπεδο
– Διαστάσεις του όγκου εισόδου (Προαιρετικό)
– Διαστάσεις του όγκου εξόδου
– Συνάρτηση ενεργοποίησης
8.Flatten: Μετασχηματίζει τον όγκου εισόδου σε επίπεδη αναπαράσταση (π.χ.
για όγκο εισόδου 64 × 32 × 32 η έξοδος θα είναι επίπεδη με 65536 νευρώνες)
9.BatchNormalization: Εφαρμόζει μετασχηματισμό για να διατηρήσει την μέση
τιμή και την τυπική απόκλιση των ενεργοποιήσεων του προηγούμενου επιπέδου στις τιμές 0 και 1 αντίστοιχα
Η μεθοδολογία περιληπτικά που θα πρέπει να ακολουθήσουμε σε βήματα είναι η εξής :
- Εισαγωγή των εικόνων του διαγωνισμού στο Kaggle : Η διαδικασία αυτή γίνεται εύκολα με την δήλωση της συμμετοχής μας στο διαγωνισμό. Όπως θα παρατηρήσουμε τα δεδομένα έχουν την εξής δομή :
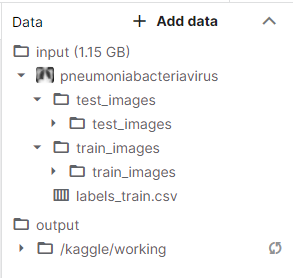
Ο φάκελος input περιλαμβάνει τα δεδομένα που θα δουλέψουμε τα οποία διαχωρίζονται σε δύο κατηγορίες:
α. στα train images τα οποία θα χρησιμοποιήσουμε για την δημιουργία του μοντέλου μας σε συνδυασμό με το αρχείο labels_train.csv στο οποίο μας δίνεται η πληροφορία για την κατηγορία κάθε εικόνας
β.στα test images όπου βρίσκονται οι εικόνες στις οποίες θα προβλέψουμε την κατηγορία στην οποία ανήκουν χρησιμοποιώντας το μοντέλο που δημιουργήσαμε και τις προβλέψεις αυτές θα τις αποθηκεύσουμε σε ένα νέο csv αρχείο στον φάκελο Output το οποίο και θα κάνουμε υποβολή στο διαγωνισμό στο kaggle.
2. Εισαγωγή απαραίτητων βιβλιοθηκών στο notebook:
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
import matplotlib.image as mplimg
from matplotlib.pyplot import imshow
from keras import layers
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
from keras.layers import Input, Dense, Activation, BatchNormalization, Flatten, Conv2D
from keras.layers import AveragePooling2D, MaxPooling2D, Dropout,GlobalAveragePooling2D
from keras.models import Model,load_model
,Sequential
import efficientnet.keras as efn
import keras.backend as K
from keras.metrics import categorical_accuracy, top_k_categorical_accuracy, categorical_crossentropy
from keras.callbacks import EarlyStopping, ReduceLROnPlateau, ModelCheckpoint
from keras.optimizers import Adam,SGD
from keras.applications import VGG19
import warnings
warnings.simplefilter("ignore", category=DeprecationWarning)Οι παραπάνω γραμμές κώδικα είναι στην ουσία οι βιβλιοθήκες που θα χρειαστούμε για να δουλέψουμε παρακάτω. Εν τάχει θα αναφέρω πώς εισάγουμε τη βιβλιοθήκη pandas η οποία είναι κάτι σαν το excel για python, το numPy, μία βιβλιοθήκη για στατιστική ανάλυση, το Keras ένα από τα πιο γνωστά frameworks για deep learning.
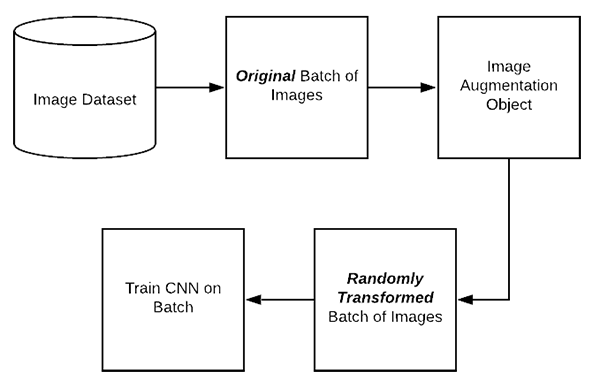
3. Data augmentation :

Προκειμένου να εκπαιδεύσουμε καλύτερα το μοντέλο μας θα χρειαστούμε όσο το δυνατόν περισσότερα δεδομένα. Επειδή αυτό δεν είναι πάντα εφικτό εφαρμόζουμε την τεχνική του data augmentation με την οποία αντικαθιστούμε τις υπάρχουσες εικόνες δημιουργώντας περισσότερες είτε αλλάζοντας τη γωνία θέασης , είτε περιστρέφοντας τις εικόνες κάποιες μοίρες κλπ .
Το Keras μας δίνει αυτή τη δυνατότητα μέσω της κλάσης ImageDataGenerator .
Έτσι λοιπόν παρακάτω φορτώνουμε τις εικόνες από το dataset και ξεκινάμε την δημιουργία των augmented data :
traindf=pd.read_csv("/kaggle/input/pneumoniabacteriavirus/labels_train.csv",dtype=str)
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
rescale=1./255,
shear_range=0.2,
zoom_range=0.25,
horizontal_flip=True,
validation_split=0.2,
fill_mode='nearest')Στο documentation της κλάσης θα βρείτε αναλυτικές πληροφορίες για όλες τις διαθέσιμες παραμέτρους. Στην παρακάτω εικόνα μπορείτε να δείτε μία απεικόνιση της μεθόδου που θα ακολουθήσουμε η οποία γίνεται on the fly χάρη στο Keras
Στη συνέχεια θα ορίσουμε κάποιες μεταβλητές τις οποίες θα χρειαστούμε παρακάτω ενώ η παραμετροποίησή τους μπορεί να μεταβάλλει την ακρίβεια του μοντέλου μας.
#Διάσταση κάθε εικόνας
IMAGE_SIZE = (224, 224)
#Αριθμός κατηγοριών που θα γίνει το classification
NUM_CLASSES = 3
#Σύνολο εικόνων που θα τροφοδοτούμε το μοντέλο κάθε φορά
BATCH_SIZE = 16
#Αριθμός layer που θα αποκλείσουμε από το CNN
FREEZE_LAYERS = 2
#Αριθμός Εποχών
NUM_EPOCHS = 1
#Filename του μοντέλου
WEIGHTS_FINAL = 'model-final.h5'Στο dataset λοιπόν που δημιουργήσαμε On the fly προηγουμένως με τις περισσότερες “πειραγμένες” εικόνες θα κάνουμε έναν διαχωρισμό όπου 80% αυτών θα είναι τα train data ενώ 20% τα train data . Ο τρόπος για να το κάνουμε αυτό είναι ώς εξής :
train_generator=datagen.flow_from_dataframe(
dataframe=traindf,
directory="/kaggle/input/pneumoniabacteriavirus/train_images/train_images/",
x_col="file_name",
y_col="class_id",
subset="training",
interpolation='nearest',
batch_size=BATCH_SIZE,
seed=42,
shuffle=True,
class_mode="categorical",
target_size=IMAGE_SIZE)
valid_generator =datagen.flow_from_dataframe(
dataframe=traindf,
directory="/kaggle/input/pneumoniabacteriavirus/train_images/train_images/",
x_col="file_name",
y_col="class_id",
subset="validation",
interpolation='nearest',
batch_size=BATCH_SIZE,
seed=42,
shuffle=True,
class_mode="categorical",
target_size=IMAGE_SIZE)Τέλος θα δημιουργήσω αντίστοιχα ένα αντικείμενο και για τα Test Data το οποίο θα το χρησιμοποιήσω αφού κάνω train το μοντέλο μου ώς εξής :
test_datagen=ImageDataGenerator(rescale=1./255.)
test_generator=test_datagen.flow_from_directory(
directory="/kaggle/input/pneumoniabacteriavirus/test_images/",
batch_size=1,
seed=42,
shuffle=False,
class_mode=None,
target_size=IMAGE_SIZE)Εδώ αξίζει να σημειωθεί πώς το batch size πρέπει να είναι πάντοτε ένα καθώς θέλουμε να γίνεται έλεγχος στις εικόνες μία προς μία και τα test δεδομένα να είναι πάντοτε με την ίδια σειρά διαφορετικά ο έλεγχος δεν θα είναι σωστός.
4. Model Training
Στο σημείο αυτό ήρθε η ώρα να κάνουμε train το μοντέλο μας. Για τις ανάγκες του tutorial επιλέξαμε ένα pretrained μοντέλο το VGG19 στο οποίο μπορούμε αφού το φορτώσουμε εαν θέλουμε να το επεκτείνουμε με τα δικά μας επιθυμητά layers.

Επίσης επειδή στο τέλος θέλουμε να ταξινομούμε σε τρεις κλάσεις , αποθηκεύουμε στην μεταβλητή preds ένα Dense Layer με τρείς νευρώνες .
base_model = VGG19(weights = "imagenet", include_top=False,input_shape = (224, 224, 3))
x = base_model.output
x = Flatten()(x)
x = Dense(120, activation = "relu")(x)
x = Dense(120, activation = "relu")(x)
x = Dense(120, activation = "relu")(x)
preds = Dense(3, activation = "softmax")(x)
model = Model(input = base_model.input, output = preds)
model.summary()Ο παραπάνω κώδικας λοιπόν θα έχει σαν αποτέλεσμα την εμφάνιση της παρακάτω πληροφορίας στην οθόνη μας :
Found 3738 validated image filenames belonging to 3 classes.
Found 934 validated image filenames belonging to 3 classes.
Found 1168 images belonging to 1 classes.
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5
80142336/80134624 [==============================] - 3s 0us/step
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv4 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv4 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv4 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 25088) 0
_________________________________________________________________
dense_1 (Dense) (None, 120) 3010680
_________________________________________________________________
dense_2 (Dense) (None, 120) 14520
_________________________________________________________________
dense_3 (Dense) (None, 120) 14520
_________________________________________________________________
dense_4 (Dense) (None, 3) 363
=================================================================
Total params: 23,064,467
Trainable params: 23,064,467
Non-trainable params: 0
_________________________________________________________________5. Early Stoppers
Ένα συχνό φαινόμενο όταν κάνουμε train ένα μοντέλο είναι το overfitting. Το Keras μας προσφέρει ορισμένα χρήσιμα εργαλεία για να το αποφύγουμε και τα οποία είναι:
α) το ModelCheckPoint : Στην ουσία αποθηκεύει το καλύτερο μοντέλο σε ένα run ανάμεσα στις εποχές που έχουμε ορίσει. Πολύ χρήσιμο καθώς δεν έχουμε πάντοτε το καλύτερο run στο τέλος.
β) το EarlyStopping : Εδώ αφού ορίσουμε το patience που θέλουμε δλδ την μετρική την οποία δηλώνουμε πόσο υπομονή θέλουμε να κάνουμε κατά την διάρκεια του train είτε κατά πάνω είτε κατά κάτω όπως επίσης μπορούμε να ορίσουμε σε ποια παράμετρο θέλουμε να δείξουμε υπομονή δηλαδή στην ακρίβεια ή στην απώλεια προκειμένου να αποφύγουμε το overfitting. Φυσικά πάντα είναι καλό να κάνουμε plotting στα δεδομένα μας προκειμένου να βλέπουμε την εξέλιξη του train.
γ) το ReduceLROnPlateau : Αρκετές φορές το μοντέλο μας δεν μαθαίνει με τον ίδιο ρυθμό , μπορεί δλδ να παρατηρήσουμε οτι ενώ ξαφνικά ανεβαίνει το σκορ μετά από κάποια βήματα αυτό ανεβαίνει απότομα ψηλά. Το συγκεκριμένο εργαλείο μειώνει το αρχικό learning rate που έχουμε ορίσει προκειμένου και πάλι να αποφύγουμε το overfitting.
Τα παραπάνω στον κώδικά μας υλοποιούνται ως εξής :
checkpoint = ModelCheckpoint(WEIGHTS_FINAL, monitor='val_accuracy',
verbose=1, save_best_only=True, mode='max')
early = EarlyStopping(monitor='val_accuracy', mode='max', min_delta=1,
patience=25, restore_best_weights=True)
callbacks_list = [checkpoint, early]6. Model fitting
Ήρθε η ώρα να κάνουμε fitting το μοντέλο ή με απλά λόγια να μετρήσουμε πόσο καλά τα πάει το μοντέλο που δημιουργήσαμε παραπάνω με τα train data. Ο παρακάτω κώδικας το υλοποιεί αυτό ενώ μπορούμε να πειραματιστούμε με τις τιμές των μεταβλητών ή και να τις αφαιρέσουμε εντελώς προκειμένου το fitting να γίνει με τα default values. Μία χρήσιμη συμβουλή είναι πώς αρκετές φορές οι default τιμές τα καταφέρνουν καλύτερα.
STEP_SIZE_TRAIN=train_generator.n//train_generator.batch_size
STEP_SIZE_VALID=valid_generator.n//valid_generator.batch_size
STEP_SIZE_TEST=test_generator.n//test_generator.batch_size
model.fit_generator(train_generator,
steps_per_epoch = train_generator.samples // BATCH_SIZE,
validation_data = valid_generator,
validation_steps = valid_generator.samples // BATCH_SIZE,
epochs = NUM_EPOCHS,
verbose=1,
callbacks=callbacks_list)
# save trained weights
model.save(WEIGHTS_FINAL)Επίσης κατά την διάρκεια της εκτέλεσης θα βλέπουμε την παρακάτω εικόνα στην οποία διακρίνουμε τις παραπάνω μετρικές όπως δηλαδή τις απώλειες , την ακρίβεια και το ποσοστό που έχουμε πετύχει. Επίσης βλέπουμε και το modelcheckpoint εν λειτουργία καθώς αποθηκεύει το καλύτερο αποτέλεσμα που έχουμε πετύχει:
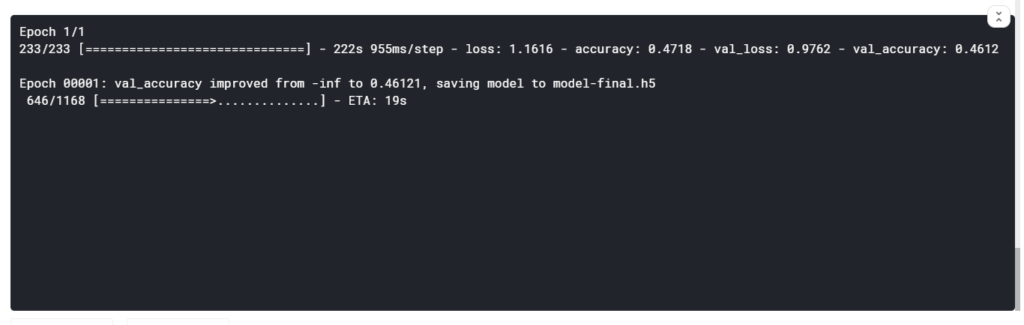
7. Predicting
Αφού χτίσαμε και αποθηκεύσαμε το μοντέλο μας προχωράμε στη διαδικασία του predicting η οποία γίνεται ώς εξής:
# load the saved model
saved_model = load_model(WEIGHTS_FINAL)
test_generator.reset()
pred=saved_model.predict_generator(test_generator,steps=STEP_SIZE_TEST,verbose=1)
predicted_class_indices=np.argmax(pred,axis=1)
labels = (train_generator.class_indices)
labels = dict((v,k) for k,v in labels.items())
predictions = [labels[k] for k in predicted_class_indices]
filenames=test_generator.filenames
results=pd.DataFrame({"file_name":filenames,
"class_id":predictions})
results.to_csv("results.csv",index=False)Πρακτικά αυτό που κάνουμε είναι να φορτώσουμε το μοντέλο που δημιουργήσαμε και να το βάλουμε να κάνει προβλέψεις στα test images που μας έχουν δοθεί από τον διαγωνισμό. Στο τέλος θα δημιουργηθεί ένα csv αρχείο το οποίο και θα πρέπει να το υποβάλλουμε προκειμένου να δούμε την κατάταξή μας. Προσοχή ένα υψηλό σκορ δεν σημαίνει πάντοτε ότι είναι και το τελικό καθώς μπορεί να έχουμε κάνει overfitting στα test results και αυτό είναι κάτι που δεν μπορούμε να το ξέρουμε.
Καλή επιτυχία.
Χρήσιμη βιβλιογραφία:
- https://keras.io/
- https://towardsdatascience.com/deep-learning-tips-and-tricks-1ef708ec5f53
- https://www.amazon.com/Hands-Machine-Learning-Scikit-Learn-TensorFlow/dp/1492032646/ref=sr_1_1?dchild=1&keywords=machine+learning&qid=1609141641&sr=8-1
- https://www.udemy.com/course/data-science-and-machine-learning-with-python-hands-on/
- ianos.gr/michaniki-mathisi-0485002
- https://www.youtube.com/user/sentdex
